
Wow…ㅋㅋㅋ
내가 고르는 문제들 족족
난이도가 미쳐 날뛰는구나…。
지금까지만 해도 쬐다 lunatic(루나틱) ōxō
지금까지만 해도 쬐다 lunatic(루나틱) ōxō


스샷.1
먼저 지문부터 대충 마이웨이 직역하면
다음과 같습니다.
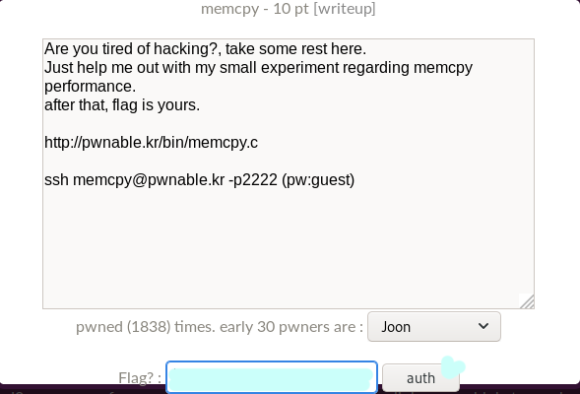
Are you tired of hacking?, take some rest here.
(으따 해킹하는 거 지겨워졌고 마이 잠깐 좀 쉬랑께?)
Just help me out with my small
experiment regarding memcpy performance.
(memcpy 성능 실험 좀 도와달랑께)
after that, flag is yours.
(그럼 키값은 니꺼랑꼐?)
음… 이번 은 해킹이 아니라고 하네요
뭐 일단 한번 보지요
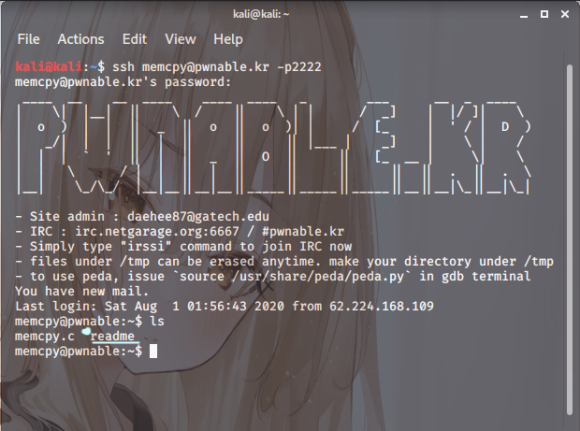
스샷.2
저번과 같은 방법으로 터미널을 열고
접속한 후 리눅스의 ls 명령어로
파일을 확인해봅니다.
음 그러니까 memcpy랑
readme 이 두 개 가 전부군요
아마 이 계정으로는 키값을 받아
챙길 수가 없겠습니다.
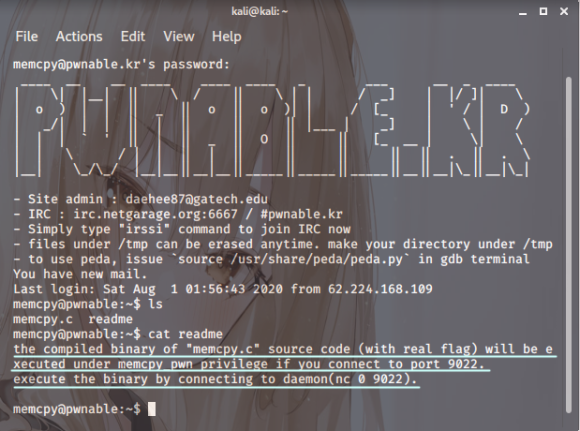
스샷.3
대략적으로 아마도 nc 리스닝으로
일시 적으로 권한 상승으로 해야지만이
키값을 받아챙길 수 있는 모양입니다.
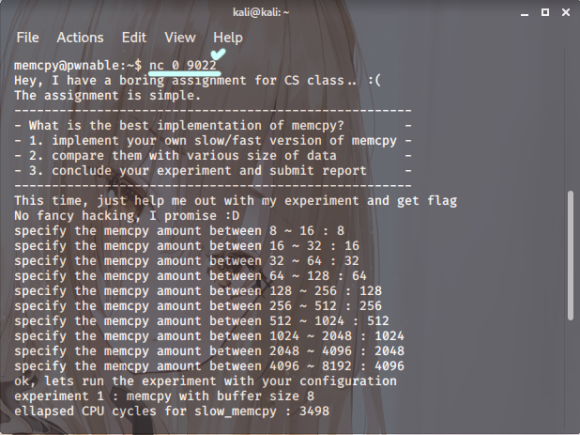
스샷.4
그럼 리스닝으로 접속해 봅시다
접속해보니 memcpy이 동작하는 것을
볼 수 있습니다. 찾아보니 이 파일은
C언어로 메모리를 복사하는 함수
로 작동하는 걸로 추측이 됩니다.
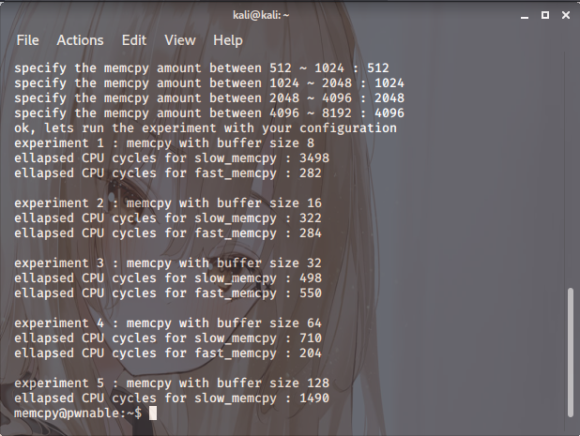
스샷. 5
memcpy 파일은 범위 내 수를 입력받습니다.
범위 수가 아니면 바로 종료되고 범위 내 수를
10번 입력받게 되면 메모리를 느린 복사와
빠른 복사 과정을 거친다고 합니다.
근데 5까지만 과정을 거치다가 갑자기
오류를 내뱉더니 죽었습니다¨。ōxō
오류를 내뱉더니 죽었습니다¨。ōxō
다시 말해 이 프로그램에는 중간 과정이 끊긴다는
문제를 발견했고 실행 시 나오는 메시지처럼
memcpy의 느리고 빠른 버전의 구현, 다양한
크기의 데이터 비교가 있는데 중간에 끊기게
하지 않고 구간을 모두 가능하면 키값을
준다고 합니다. 그럼 소스코드를 분석해 봅시다.
// compiled with : gcc -o memcpy memcpy.c -m32 -lm
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <sys/mman.h>
#include <math.h>
unsigned long long rdtsc(){
asm("rdtsc");
}
char* slow_memcpy(char* dest, const char* src, size_t len){
int i;
for (i=0; i<len; i++) {
dest[i] = src[i];
}
return dest;
}
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ (
"movdqa (%0), %%xmm0\n"
"movdqa 16(%0), %%xmm1\n"
"movdqa 32(%0), %%xmm2\n"
"movdqa 48(%0), %%xmm3\n"
"movntps %%xmm0, (%1)\n"
"movntps %%xmm1, 16(%1)\n"
"movntps %%xmm2, 32(%1)\n"
"movntps %%xmm3, 48(%1)\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}
int main(void){
setvbuf(stdout, 0, _IONBF, 0);
setvbuf(stdin, 0, _IOLBF, 0);
printf("Hey, I have a boring assignment for CS class.. :(\n");
printf("The assignment is simple.\n");
printf("-----------------------------------------------------\n");
printf("- What is the best implementation of memcpy? -\n");
printf("- 1. implement your own slow/fast version of memcpy -\n");
printf("- 2. compare them with various size of data -\n");
printf("- 3. conclude your experiment and submit report -\n");
printf("-----------------------------------------------------\n");
printf("This time, just help me out with my experiment and get flag\n");
printf("No fancy hacking, I promise :D\n");
unsigned long long t1, t2;
int e;
char* src;
char* dest;
unsigned int low, high;
unsigned int size;
// allocate memory
char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
size_t sizes[10];
int i=0;
// setup experiment parameters
for(e=4; e<14; e++){ // 2^13 = 8K
low = pow(2,e-1);
high = pow(2,e);
printf("specify the memcpy amount between %d ~ %d : ", low, high);
scanf("%d", &size);
if( size < low || size > high ){
printf("don't mess with the experiment.\n");
exit(0);
}
sizes[i++] = size;
}
sleep(1);
printf("ok, lets run the experiment with your configuration\n");
sleep(1);
// run experiment
for(i=0; i<10; i++){
size = sizes[i];
printf("experiment %d : memcpy with buffer size %d\n", i+1, size);
dest = malloc( size );
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
slow_memcpy(dest, src, size); // byte-to-byte memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for slow_memcpy : %llu\n", t2-t1);
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
fast_memcpy(dest, src, size); // block-to-block memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for fast_memcpy : %llu\n", t2-t1);
printf("\n");
}
printf("thanks for helping my experiment!\n");
printf("flag : ----- erased in this source code -----\n");
return 0;
}
앞에서 experiment5에서 fast_memcpy 구간에서
오류가 생겨 그 뒷부분이 끊겨 아래 구간이 모두
통과가 돼야 키값을 구할 수가 있습니다.
// run experiment
for(i=0; i<10; i++){ //
size = sizes[i];
printf("experiment %d : memcpy with buffer size %d\n", i+1, size);
dest = malloc( size ); //
memcpy(cache1, cache2, 0x4000); //
t1 = rdtsc(); //
slow_memcpy(dest, src, size); //
t2 = rdtsc();
printf("ellapsed CPU cycles for slow_memcpy : %llu\n", t2-t1);
memcpy(cache1, cache2, 0x4000);
t1 = rdtsc();
fast_memcpy(dest, src, size); //
t2 = rdtsc();
printf("ellapsed CPU cycles for fast_memcpy : %llu\n", t2-t1);
printf("\n");
}
printf("thanks for helping my experiment!\n");
printf("flag : ----- erased in this source code -----\n");
return 0;
}
1. 입력받은 횟수만큼 10번 진행
2. 정해준 사이즈만큼 동적으로 메모리 할당하고 이는 dest 저장
3. rdtsc()는 정확한 시간을 측정하는 함수로 느린 메모리 복사를 진행한 시간 구하고 t1에 저장
4. t2 또한 빠른 메모리 복사를 진행한 시간이 들어간다.
5. 느린 메모리 복사와 빠른 메모리 복사는 각각 바이트 단위, 블록 단위 복사를 진행.
→ 해결책 : 우선 느린 메모리 복사 함수와 빠른 메모리 복사가 정의된 함수
부분으로 이동해서 함수를 파악해야 할 것입니다.
다음 slow_memcpy, fast_memcpy 함수입니다.
char* slow_memcpy(char* dest, const char* src, size_t len){
int i;
for (i=0; i<len; i++) {
dest[i] = src[i];
}
return dest;
}
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){ //길이가 64이상만 아래 빠른 복사 이용
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ (
"movdqa (%0), %%xmm0\n"
"movdqa 16(%0), %%xmm1\n"
"movdqa 32(%0), %%xmm2\n"
"movdqa 48(%0), %%xmm3\n"
"movntps %%xmm0, (%1)\n"
"movntps %%xmm1, 16(%1)\n"
"movntps %%xmm2, 32(%1)\n"
"movntps %%xmm3, 48(%1)\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}
slow_memcpy는 src에서 dest로 바이트 단위
하나하나 쉽지만 느린 방법으로 복사합니다.
반면 fast_memcpy()는 사이즈가 64바이트
미만인 경우만 slow_memcpy를 실행
64바이트 이상일 경우 어셈블리어로
이루어진 코드를 실행합니다.
fast_memcpy() 부분에서
중간에 실행하다가 끊겼기 때문에
이 어셈블리 코드가 멱여들지 않아 오류를 냈습니다.
이걸 분석하면 다음과 같습니다.
__asm__ __volatile__ (
"movdqa (%0), %%xmm0\n"
"movdqa 16(%0), %%xmm1\n"
"movdqa 32(%0), %%xmm2\n"
"movdqa 48(%0), %%xmm3\n"
"movntps %%xmm0, (%1)\n"
"movntps %%xmm1, 16(%1)\n"
"movntps %%xmm2, 32(%1)\n"
"movntps %%xmm3, 48(%1)\n"
::"r"(src),"r"(dest):"memory");
movdqa : 정렬된 더블 쿼드 워드 이동
소스 피어 연산자 (두 번째 피연산자)의
이중 쿼드 워드를 대상 피연산자
(첫 번째 피연산자)로 이동합니다.
이 명령어는 더블 쿼드 워드를
XMM 레지스터와 128비트
메모리 위치 간에 또는 두 개의
XMM 레지스터 간에 이동하는
데 사용할 수 있습니다.
소스 또는 대상 피연산자가
메모리 피연산자 인 경우
피연산자는 16바이트 경계에 정렬되어야 하면
그렇지 않으면 일반 보호 예외(#GP)가 생성.
movntps : 비 임시 힌트를 사용해 포장된 단일 정밀도 부동 소수점 값 저장
비 휘발성 힌트를 사용해 소스 피연산자의 압축된 부동 소수점 값을 대상
피연산자로 이동해 메모리에 쓰는 동안 데이터 캐싱을 방지합니다.
movdqa에서 mov가 값을 이동시키는 명령인데 dq가 더블
쿼드인듯합니다. 이 명령어는 16바이트 경계에 정렬되지
않으면 예외가 발생하고 피연산자인 dest의 주소가 16바이트
단위로 만들어준다면 16바이트 경계에 정렬되어 해결될 것입니다.
자 그리고 gdb를 사용해서 디버깅으로 키값을 받아 챙겨봅시다 ㅋㅅㅋ
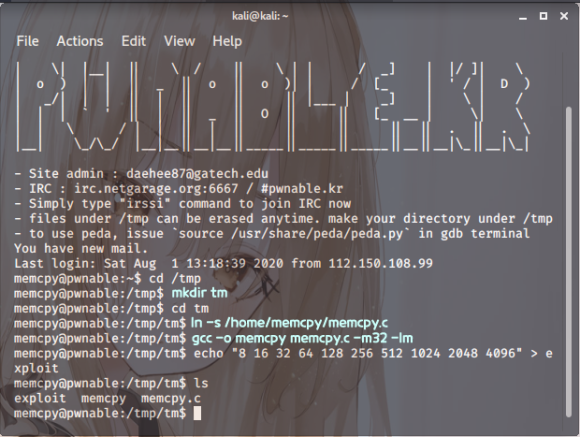
스샷. 6
cd /tmp
mkdir tm
cd tm
ln -s /home/memcpy/memcpy.c
gcc -o memcpy memcpy.c -m32 -lm
echo "8 16 32 64 128 256 512 1024 2048 4096" > exploit
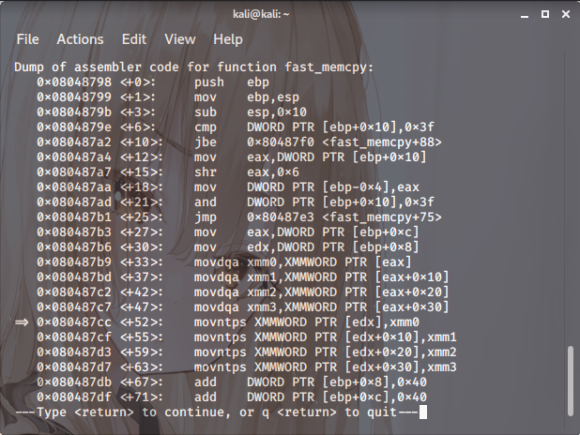
그리고 gdb를 통해 실행을 한 뒤 fast_memcpy 함수에 들어가서 살펴봅시다.
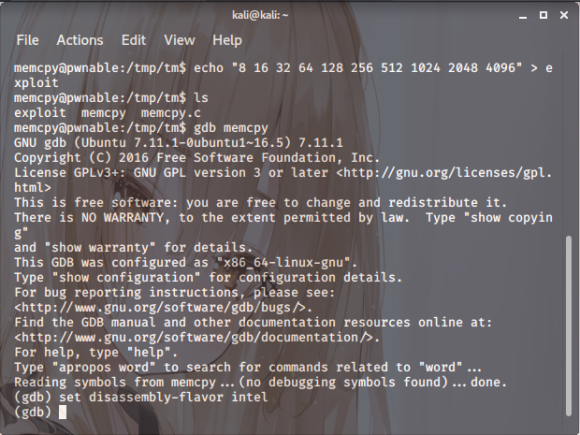
스샷. 7
저 위치에 머물러 있고 edx 값이 0x080487cc입니다.
4번째까지는 정령이 되어있어서 오류가 안 생겼지만
5번째에서는 정렬이 되지 않았습니다.
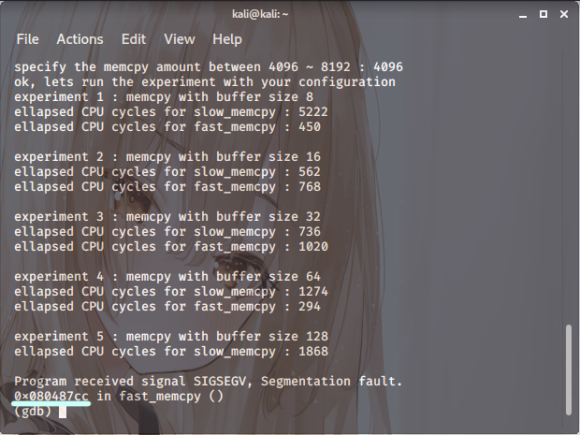
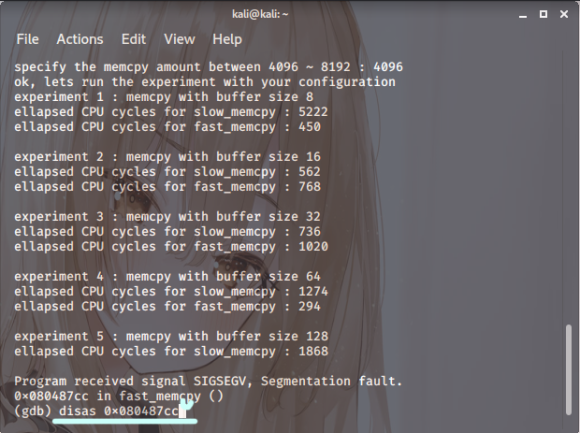
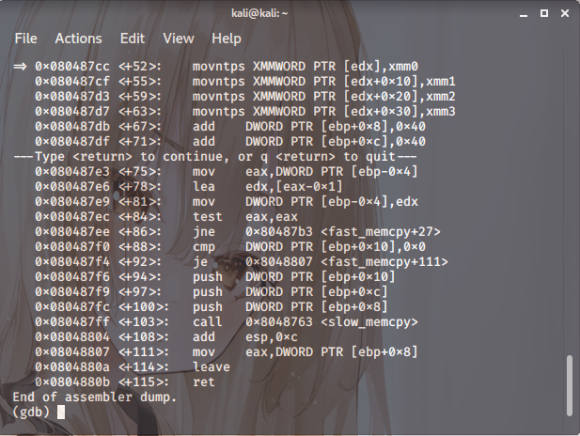
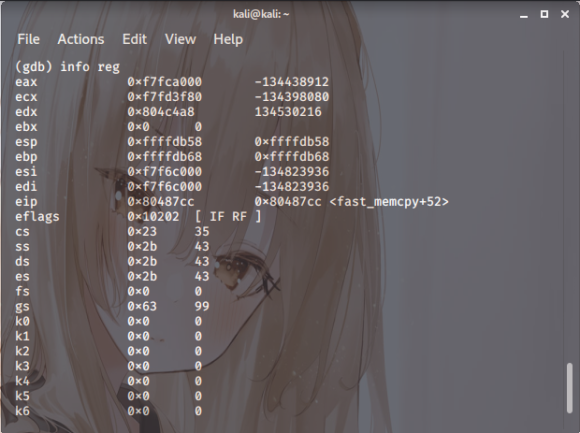
스샷. 8
fast_memcpy 함수+71 위치에 브레이크 포인트를
걸고 레지스터의 값을 확인하면 edx가 804d060으로
정렬이 되어있음을 알 수 있겠습니다.
즉 다시 말해 64에서 8이 부족하기 때문에
8씩 당겨져야 하고 나머지 값을 디버깅하게 됨
그것들도 모두 8이 모자라다는 것을 추측됩니다.
그래서 5를 비롯한 그 뒤의 나머지 값이 8씩 다 더해주어서
8 16 32 64 128 256 512 1024 2048 4096
8 16 32 72 136 264 520 1032 2056 4096
위의 형태를 갖추게 됩니다.
자 이제 추측한 이걸 토대로
nc 리스닝 서버를 열어제껴서
각각 넣어주게 되면은 키값을
받아챙겨갈 수 있게 됩니다.
물론 이거 말고도 다른 방법이 있겠지만
본인은 gdb를 이용하는 방법이 제일
좋겠다고 생각됩니다.
이리하여 프로그램을 실행하다 보면
아래와 같이 키값이 나옵니다
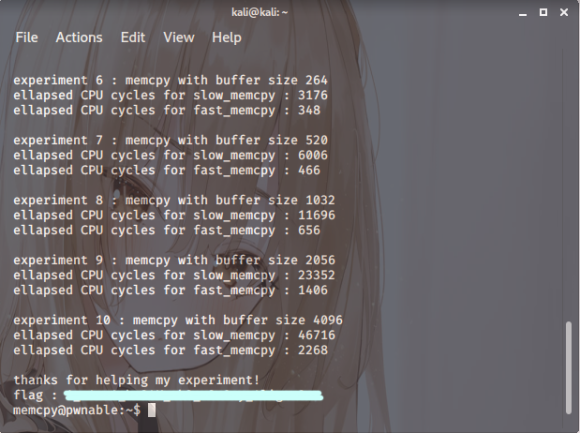
스샷. 9
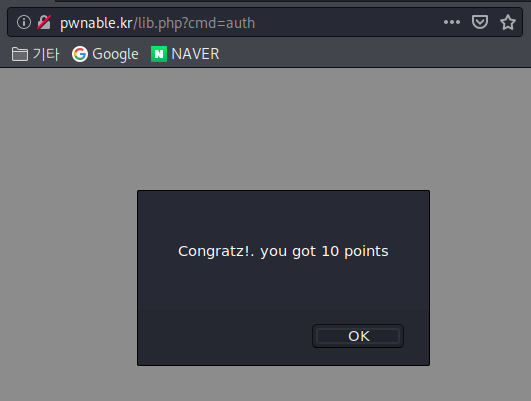
받아챙긴 키값으로 다시 처음으로 돌아와서
빈칸에 채워 넣고 auth 버튼 누르면
스샷.10
이렇게 10포인트를 받았다는 메시지와
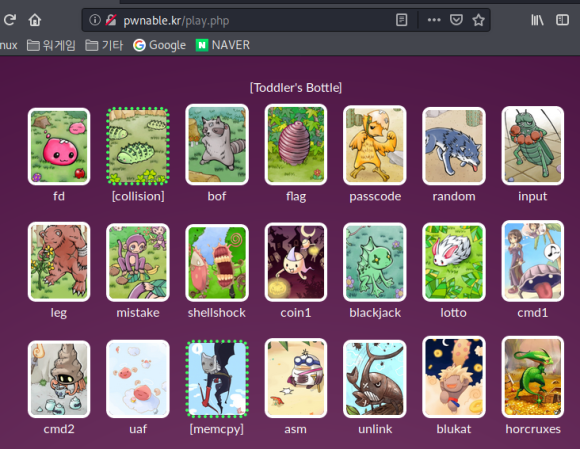
스샷.11
그리고 돌아와보면 이렇게
풀었다는 뜻으로 녹색 점선으로
표시가 되었습니다.
긴 글을 보시느라 감사합니다.
수고하셨습니다:)

좋은 하루 되시고 하시는 일 잘 되시고
날이 덥습니다 더위 먹지 않게 유의하시고
코로나 조심하세요

'모의해킹 > [CTF] pwnable.kr' 카테고리의 다른 글
| [pwnable.kr]_Random문제풀이 (0) | 2022.02.27 |
|---|---|
| [pwnable.kr]_Ieg문제풀이 (0) | 2022.02.27 |
| [pwnable.kr]_Input문제풀이 (0) | 2022.02.27 |
| [pwnable.kr]_passcode문제풀이 (0) | 2022.02.27 |
| [pwnable.kr]_Collision 문제풀이 (0) | 2022.02.27 |
모의해킹/[CTF] pwnable.kr





